웹 서비스를 배포 했을 때, 일반적으로 사용자는 브라우저를 통해서 배포한 웹 페이지에 접근한다.
이 과정을 간략히 요약해보자.
브라우저가 80번 포트로 웹 서버 (WAS)에 접근해 html, css, javascript 파일을 읽어들인다.
(읽어 들일 때 한번에 다 받는것이 아닌 여러번에 걸쳐 나누어 받는다)
html 에서는 DOM 구조를 설정하고 (뼈대를 구성한다)
css 에서 스타일 속성을 부여하며
javascript 에서 동작을 부여한다.
우리가 매일 사용하고 있는 브라우저는 사실 많은 동작을 수행하고 있다.
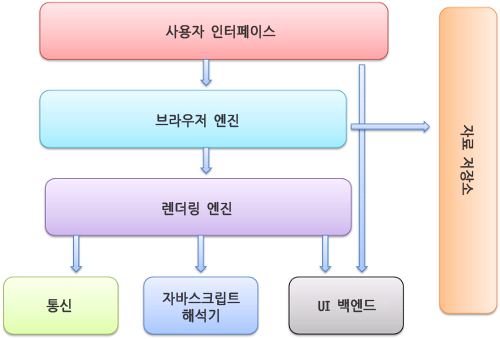
웹 브라우저의 구성 요소
이러한 브라우저의 구성 요소에는 아래와 같은 것들이 존재한다.
- 사용자 인터페이스
- 브라우저 엔진
- 렌더링 엔진
- 통신
- UI 백엔드
- 자바스크립트 해석기
- 자료 저장소
여기서 앞에서 설명한 방식대로 (html, css, javascript) view를 렌더링하는 '렌더링 엔진'에 대해서 알아보자.
렌더링 엔진의 동작 과정
렌더링 엔진의 동작 순서는 다음과 같다.
-
DOM 트리 구축을 위한 HTML 파싱
-
렌더 트리 구축
-
렌더 트리 배치
-
렌더 트리 그리기
여기서 1번 DOM 트리 구축을 위한 HTML 파싱 부분을 자세히 살펴보자.
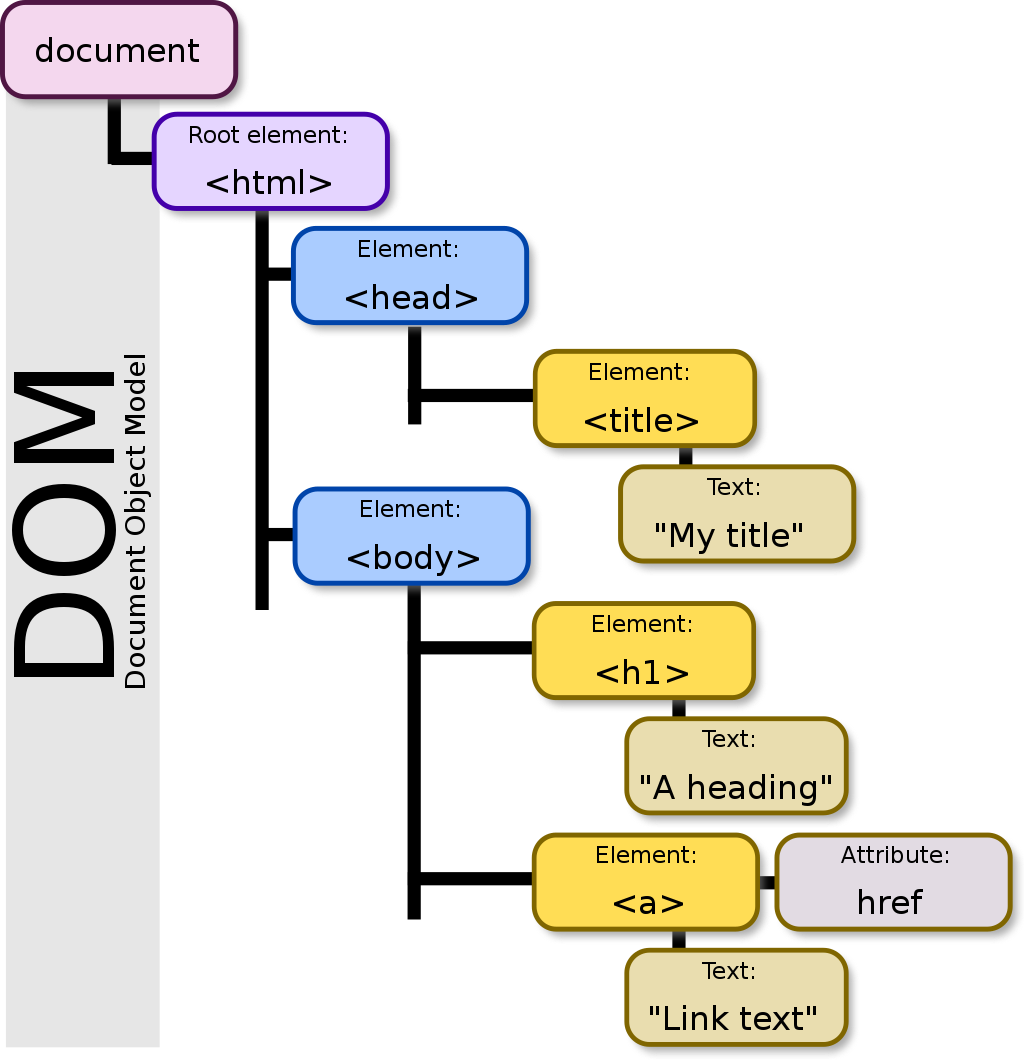
DOM 은 Document Object Model의 약자이다.
위키피디아에서는 이를 문서 객체 모델이라고 번역했다.
위 그림을 보면 html 문서와 많이 비슷해 보이지 않는가??
바로 들여쓰기로 정렬된 html 문서의 구조와 트리구조가 비슷하다는 것을 알 수 있다.
렌더링 트리의 주요 동작 중 하나는, html 문서를 파싱해 트리구로조 변환한다는 것이다!
물론 html 만으로 구성된 트리는 뼈대만 있는 구조이다.
스타일을 적용하기 위해 css또한 css 파서를 이용해 파싱 후 CSS 트리를 생성한다.
렌더링 엔진은 최종적으로 DOM 트리 CSS 트리를 합쳐 렌더링 트리를 만든다.
여기서 재미있는 점은, html 문서에서 태그가 제대로 닫히지 않는 문제가 발생하더라도,
오류가 발생하지 않는다는 것이다!
브라우저 동작을 더 빠르게!
작성한 코드 (html css js 등을 편의상 코드라 부르겠다)를 브라우저에 더 빨리 렌더링 할 수 있는 방법은 무엇일까??
이를 웹 사이트 최적화 라고도 하며, 자잘한 팁들이 있어 소개하고자 한다.
css와 javascript의 위치
html 파일에서 css파일과 javascript 파일을 읽는 코드의 위치를 다음과 같이 해보자.
css : 상단
javascript: 하단
css파일의 경우 렌더링 트리를 구성하는 데 중요한 역할을 하기 때문에, DOM 트리가 만들어질 때 이미 생성되어 있다면 바로 렌더링 할 수 있을것이다.
브라우저는 파일을 다운로드 할 때까지 DOM 트리 구성을 멈추므로, html 문서 중간에 javascript 파일이 존재한다면 DOM 트리를 생성하는 것을 멈출 것이다.
이미지 잘라서 사용하기
브라우저는 한번에 읽어들일 수 있는 이미지의 수가 제한적이다 (렌더링 시 다운로드 하는 이미지)
따라서 페이지 UI에 필요한 이미지의 경우, 파일 하나로 다운을 받고 필요한 부분별로 쪼개 쓰는 방식을 사용한다면 초기 로딩시 읽어들여야 하는 이미지의 수를 줄일 수 있다.
브라우저는 다양한 기능을 수행한다.
그리고 브라우저 렌더링을 최적화 하기 위해 다양한 기술들이 존재하고 있다.
리액트의 경우 하위 컴포넌트가 변경되었을 때 전체를 다시 render하지 않도록 하기 위해 Virtual DOM (가상 DOM) 기술을 이용하고 있다.
그만큼 브라우저의 렌더링이 시스템 자원을 많이 잡아 먹는다는것에 대한 반증일 수 도 있다.
다음 질문에 답해보자
Q : 우리가 흔히 브라우저 탐색을 할 때 스크롤을 하거나, 어떤 것을 클릭하면서 화면의 위치를 바꿀 때, 브라우저는 어떻게 다시 화면을 그릴까요?
A : 처음 브라우저를 로딩할 때 생성된 렌더링 트리를 메모리에 캐싱한다. 스크롤 등의 작업을 통해 화면의 위치가 바뀌작은변화가 일어난다면 repainting의 과정만 거쳐 시스템 자원을 아낄 수 있다.

'front-end > 부스트코스 web' 카테고리의 다른 글
| [부스트 코스] JavaScript 스코프 (0) | 2020.03.04 |
|---|---|
| [부스트 코스] JavaScript 타입 (0) | 2020.02.24 |
| [부스트 코스] JavaScript 첫 걸음 (0) | 2020.02.17 |
| [부스트 코스] Request, Response 객체 (0) | 2020.02.10 |
| 웹의 동작 (0) | 2020.01.19 |