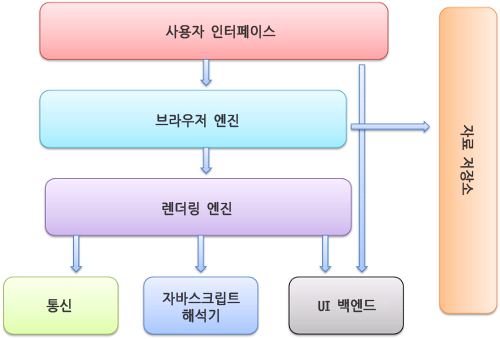
앞의 글에서 자바스크립트에는 타입이 다음과 같은 것들이 존재한다고 설명했다.
undefined, null, boolean, number, string, object, function, array, Date, RegExp
- 자바스크립트에서 타입은 선언할 때가 아니고, 실행타임에 결정된다. (실제 그 타입의 변수가 실행되는 경우)
- 함수 안에서의 파라미터나 변수는 실행될 때 그 타입이 결정된다
위 성질은 자바스크립트가 컴파일을 총 2번 하기 때문에 일어난다.
자세한 컴파일 과정은 다음과 같다.
- 함수, 변수들 호이스팅하며 선언한다.
- 선언된 객체들에게 값을 할당한다.
몇몇 타입들은 typeof 를 이용해 타입을 검사할 수 있다.
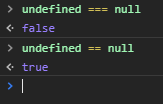
- undefined : 변수가 정의되지 않거나 값이 없을 때
- number : 데이터 타입이 수일 때
- string : 데이터 타입이 문자열일 때
- boolean : 데이터 타입이 불리언일 때
- object : 데이터 타입이 함수, 배열 등 객체일 때
- function : 변수의 값이 함수일 때
- symbol : 데이터 타입이 심볼일 때
심볼 타입
위 타입들 중 대부분은 이해가 가능하지만, 심볼 타입은 도데체 무엇일까?
심볼은 es6에서 추가된 새로운 타입이다.
유일한 객체의 프로퍼티 키(property key)를 만들기 위해 사용한다.
key로 사용했을 때, 다른것들과 절대 충돌이 나지 않는 점을 이용한다.
ES6의 class에서 private한 객체를 만들 때 사용할 수 있다.
const Count = (() => {
const count = Symbol('COUNT');
class Count {
constructor() {
this[count] = 0;
}
getScore() { return this[count]; }
setScore(score) { this[count] = score; }
}
return Count;
})();
const test = new Count();위와 같이 선언했을 때, test.count에 접근할 수 없다.
하지만 이 방법으로 완전히 private한 요소를 만들 수 있는 것은 아니다.
다음과 같은 방법으로 test.count에 접근할 수 있다.
const testSymbol = Object.getOwnPropertySymbols(test)[0];
test[testSymbol] = 20 // this is count원시 타입 vs 참조 타입
위 타입을 기본형(원시 타입)과 참조형(참조 타입)으로 나눌 수 있는데 이는 C언어에서 call by value, call by reference의 차이로 이해하면 쉽다.
원시 타입 (Primitive) : call by value
- Number
- String
- Boolean
- null
- undefined
참조 타입 (Reference) : call by reference
- Object
- Array
- Function
- RegExp
두 타입의 차이를 알아보기 위해 다음의 예제를 실행해보자
// 원시 타입의 경우
let a = 3;
let b = a;
b = 2; // 2
a // 3
// 참조 타입의 경우
let objA = { value : 3 }
let objB = objA
objB.value = 2;
objA // {value: 2}objA는 객체 (Object)타입 이므로 objB = objA 를 수행했을 때, objB는 objA의 주소를 가진다.
그렇다면 참조 타입에서 '값 복사'를 하려면 어떻게 해야 할까?? (주소를 복사하지 않음)
Object.assign()을 이용한다. (객체의 depth가 1단계만일때)
function cloneObject(obj) {
return Object.assign({}, obj);
}위 함수의 경우 obj의 depth가 1단계 만이라면, (최대 depth가 1단계) 객체를 값 복사 할 수 있다!
다음과 같은 객체의 경우 유효하다.
// 자식들이 원시 타입이다.
let obj = {
child1 : 10,
child2 : "hello",
child3 : undefined,
child4 : null
}허나 Object.assign의 경우 자식이 참조 타입인 경우 자식에 대한 복사는 다시 참조 복사를 해버리는 문제가 발생한다.
이러한 복사를 얕은 복사 라고 한다.
이 경우 다음 방법을 이용한다.
JSON.parse() & JSON.stringify()을 이용한다.
JSON.stringify(obj)는 obj의 형태를 문자열로 치환해준다.
let obj = {
child1 : 10,
child2 : "hello",
child3 : undefined,
child4 : null
}
JSON.stringify(obj) // "{"child1":10,"child2":"hello","child4":null}"JSON.parse("string")의 경우 "string"을 객체로 복구한다.
let str = JSON.stringify(obj)
JSON.parse(str) // {child1: 10, child2: "hello", child4: null}두 메소드를 합치면 객체를 깊은 복사 할 수 있다.
허나 이 방법은 매우 느리므로 정말 깊은 복사를 해야 할 때만 이용하도록 하자.
(문자열 치환후 다시 객체로 복구하므로...)
함수의 반환 타입은 무엇인가?
function printName(firstname) {
var myname = "jisu";
var result = myname + " " + firstname;
}위 코드를 실행했을 때, printName의 반환값은 무엇일까?
답은 undefined이다.
자바스크립트 함수는 반드시 return값이 존재하며, 없을 때는 기본 반환값인 'undefined'를 반환한다.
실제 개발을 해보다 보면, 자바스크립트의 타입 때문에 생기는 에러가 자주 발생한다.
다음 객체를 비동기로 받아 사용한다고 생각해보자.
let res = {
hello : "world"
}만약 API에서 res를 제대로 받아온다면 res.hello를 실행했을 때 문제가 없을 것이다.
그러나 res를 제대로 받아오지 못한다면 (res가 undefined)라면 res.hello는 undefined일 것이다.
이 경우 res.hello는 원시타입이므로 큰 문제가 발생하지 않을 수 있지만 함수등의 경우는 어떨까?
let res = {
func : () => { // do something }
}위 경우 res가 undefined인 상태에서 res.func()를 실행하려고 한다면 에러가 발생한다.
이런 타입과 관련한 에러를 직접, 실행하던 도중에 발견한다면 찾는데 시간이 오래 걸린다.
자바스크립트 타입에 관련한 에러를 컴파일시 발견할 수 있게 만든것이 타입스크립트다.
타입스크립트
https://www.typescriptlang.org/
TypeScript - JavaScript that scales.
State of the art JavaScript TypeScript offers support for the latest and evolving JavaScript features, including those from ECMAScript 2015 and future proposals, like async functions and decorators, to help build robust components. These features are avail
www.typescriptlang.org
node를 사용하고 있다면 다음 명령을 통해 설치할 수 있다.
npm install -g typescript
타입스크립트와 자바스크립트는 다음과 같은 차이가 존재한다.
var a = 1; // number
var b = '2'; // string
console.log(a+b) // "12"var a:number = 1;
var b:string = '2';
console.log(a+b)첫 번째 코드는 javascript 코드이다. a와 b가 다른타입인데 + 연산을 수행하고, 이 연산이 문자열의 합을 출력한다.
이는 생각보다 자주 발생할 수 있는 문제인데, 특히 숫자의 경우 문자열로 처리한 뒤 저장할 수 있기 때문이다.
타입스크립트에서는 a와 b의 타입을 지정해 줄 수 있으므로 연산 전에 에러를 발생시킨다.
대부분의 초보자가 자바스크립트를 접할 때 가장 난해하게 여기는 것이 바로 타입이라고 생각한다.
특히 처음 배울 때 변수에 어떤 값이던 할당할 수 있다는 점은 복잡한 프로그램을 개발하기 어렵게 한다.
실제 로직을 구현했다 하더라고 타입때문에 에러가 발생하는 경우 이를 파악하기 힘들 수도 있다.
만약 자바스크립트에 한계를 느끼기 시작했다면, 타입스크립트로 옮겨갈 기회이다!

'front-end > 부스트코스 web' 카테고리의 다른 글
| [부스트코스] 브라우저 Event (0) | 2020.03.09 |
|---|---|
| [부스트 코스] JavaScript 스코프 (0) | 2020.03.04 |
| [부스트 코스] JavaScript 첫 걸음 (0) | 2020.02.17 |
| [부스트 코스] Request, Response 객체 (0) | 2020.02.10 |
| [부스트 코스] 브라우저의 동작 방식 (렌더링 관점) (0) | 2020.02.03 |